SpringCloudAlibaba
Nacos 服务注册
Nacos服务端
- 下载地址:https://github.com/alibaba/nacos/releases
- Windows启动Nacos执行bin目录下面的startup.cmd
- 启动之后你会发现莫名其妙的报了一大堆错误,我Nacos1.4.0版本的,默认启动是启动的集群模式的Nacos;这时我们需要打开cmd命令复制代码执行(standalone代表着单机模式运行,非集群模式):
.png)
1 | # Ps: 启动集群模式只需要执行startup.cmd |
Nacos客户端
- 使用Nacos需要在父pom或者子pom引入spring cloud alibaba依赖,根据官网选择你需要的版本:https://github.com/alibaba/spring-cloud-alibaba/tags
- 代码传送门: https://github.com/jiushiboy/springcloud
- cloudalibaba-consumer-nacos-order83 –> 消费者
- cloudalibaba-provider-payment9001 –> 生产者1
- cloudalibaba-provider-payment9002 –> 生产者2
- Ps: Nacos自动集成了Ribbon调用可以从依赖中找到Netflix;
- Ps: Nacos即支持CP也支持AP,CP模式支持注册持久化实例,AP则是临时支持注册实例,那么如何切换模式呢?
1 | curl -X PUT '$NACOS_SERVER:8848/nacos/v1/ns/operator/switches?entry=serverMode&value=CP' |
Nacos配置中心Config
客户端代码传送门
- https://github.com/jiushiboy/springcloud/tree/master/cloudalibaba-config-nacos-client3377
- Ps: Nacos动态刷新功能需要使用@RefreshScope注解,实现配置自动刷新;
- 官网参照传送门:https://nacos.io/zh-cn/docs/quick-start-spring-cloud.html
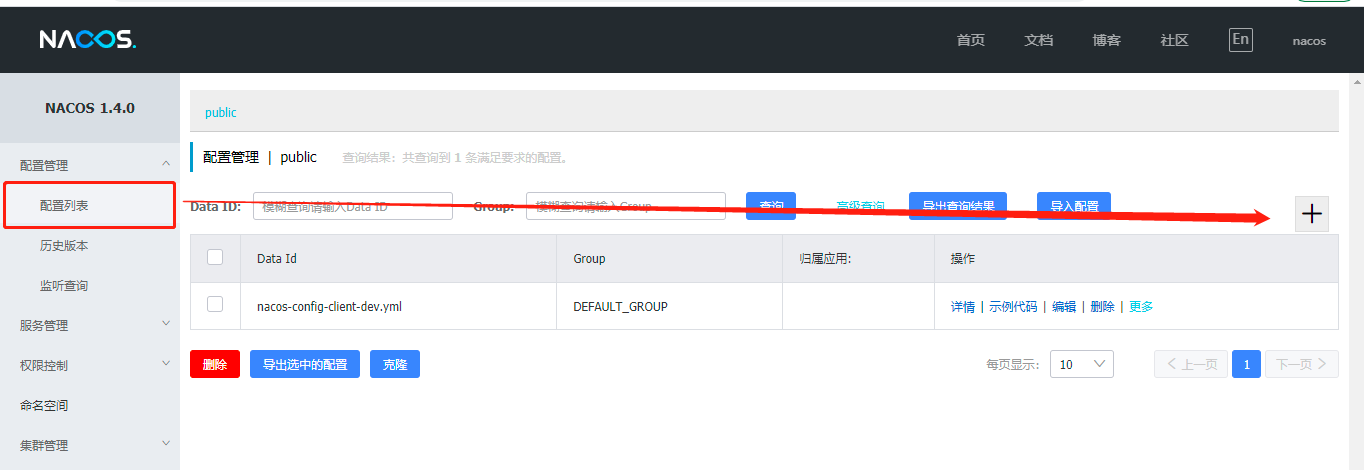
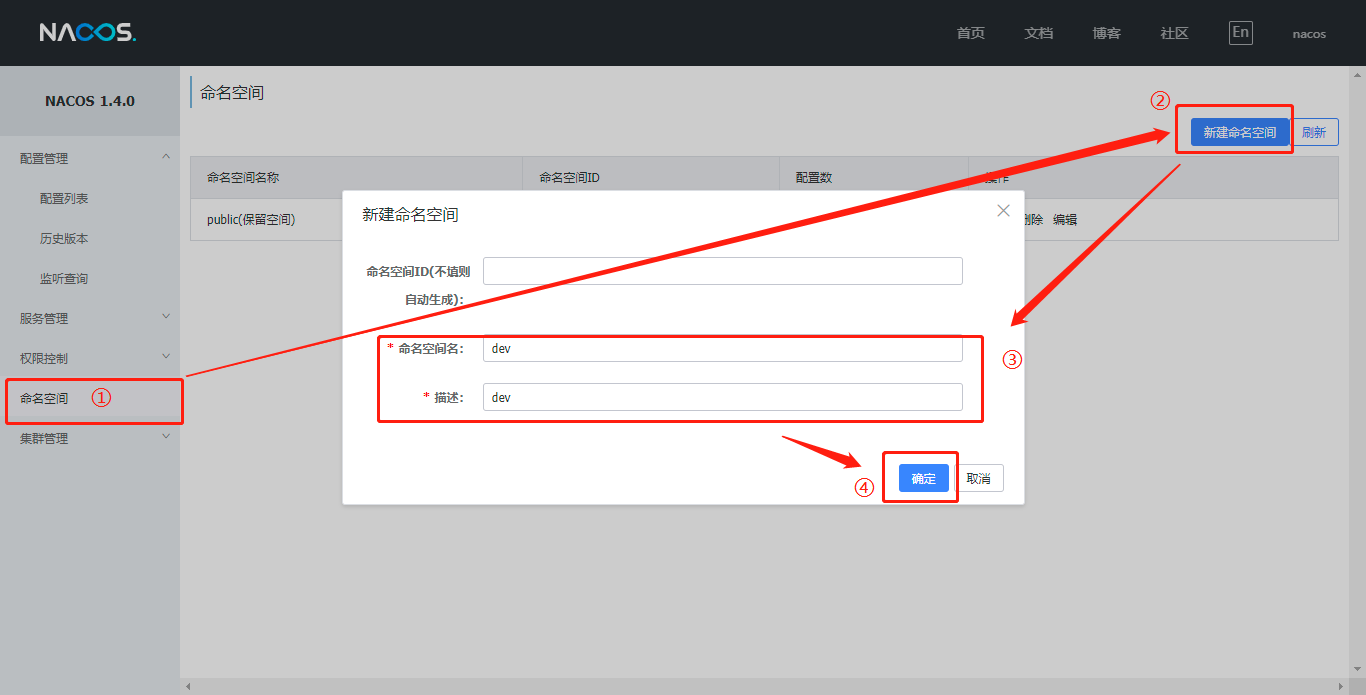
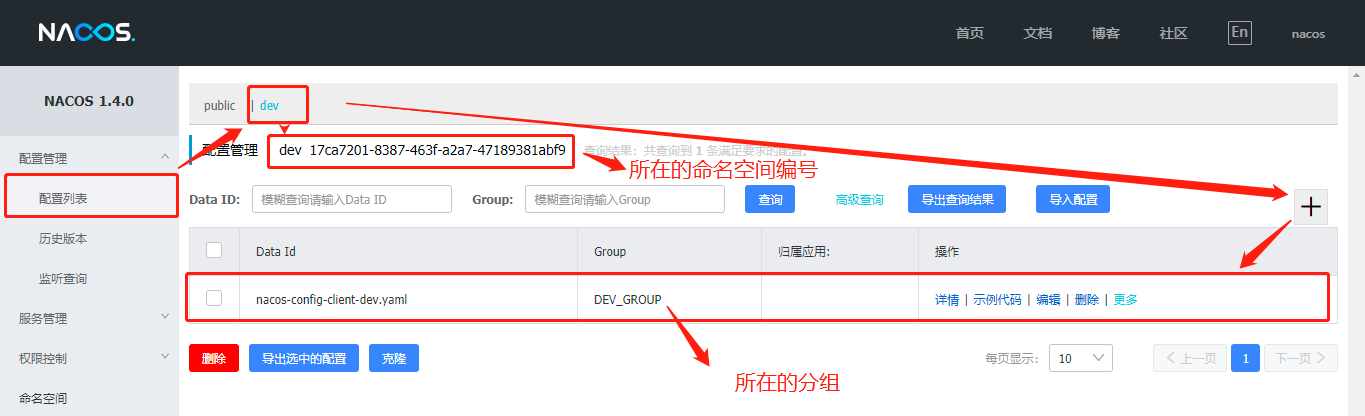
- 在Nacos的服务端添加配置
- 图二有个小坑,在新建配置时,后缀使用yml的时候,由于nacos并没有做支持,仅支持yaml,所以你删除原来的重新建一个后缀.yaml的就好了;
- 如果你实在是看不懂请回到上面的官网传送门,好好翻阅文档,稍后再试;
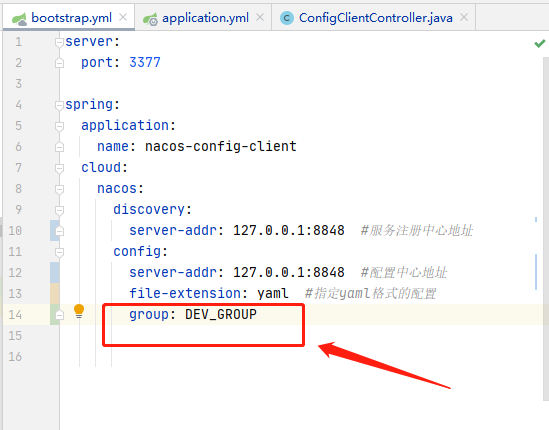
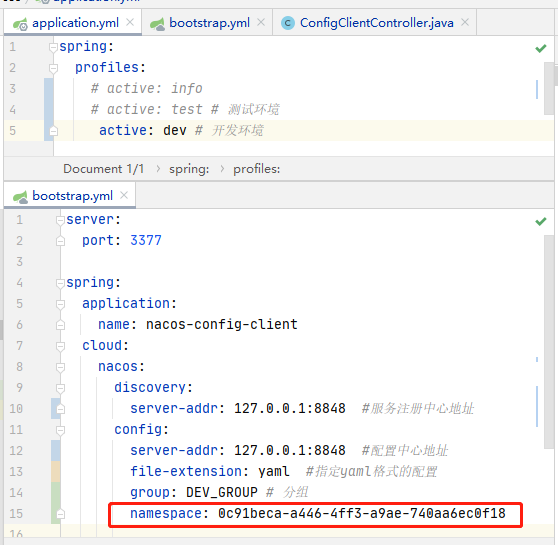
- Ps: 服务会有application.yml与bootstrap.yml两个配置文件,后者会覆盖前者的配置,可以在application.yml中指定使用哪个环境的配置文件;
1 | spring: |
- Nacos配置失败(java.lang.IllegalStateException: failed to req API:/nacos/v1/ns/instance after all server)
1 | 删除Nacos安装目录中data中的数据,重启nacos |
配置Config分组
Nacos集群与持久化配置
//TODO
Sentinel熔断与限流
Sentinel服务端安装
- 下载地址: https://github.com/alibaba/Sentinel
- 我下载的是1.8.0版本,运行命令(默认端口号为8080):
1 | java -jar sentinel-dashboard-1.8.0.jar |
- 访问localhost:8080
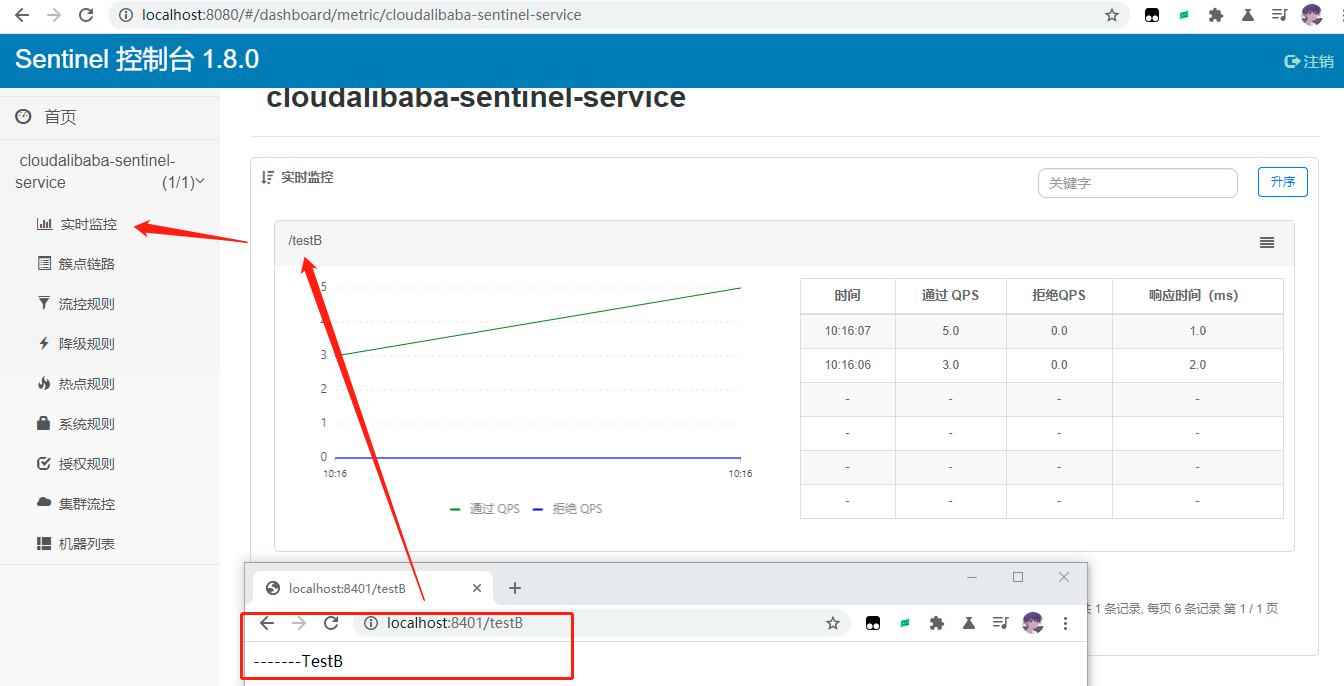
Sentinel客户端
- 下载地址: https://github.com/jiushiboy/springcloud/tree/master/cloudalibaba-sentinel-service8401
- Sentinel默认为懒加载,需要访问客户端调用一次服务才会加载;
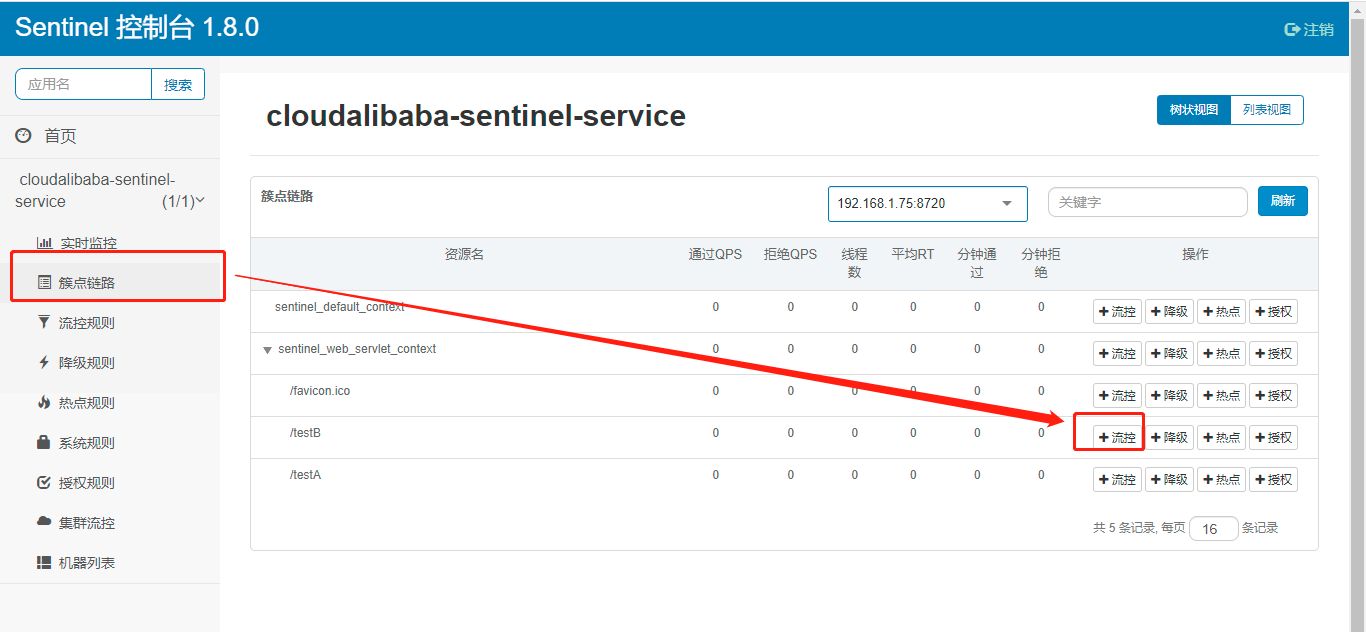
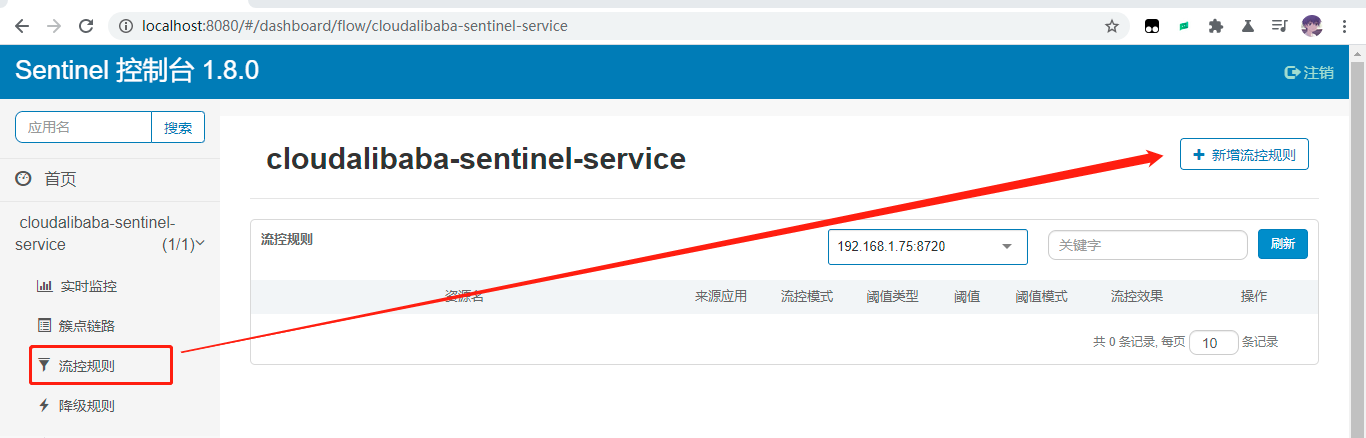
Sentinel 1.8.0流控
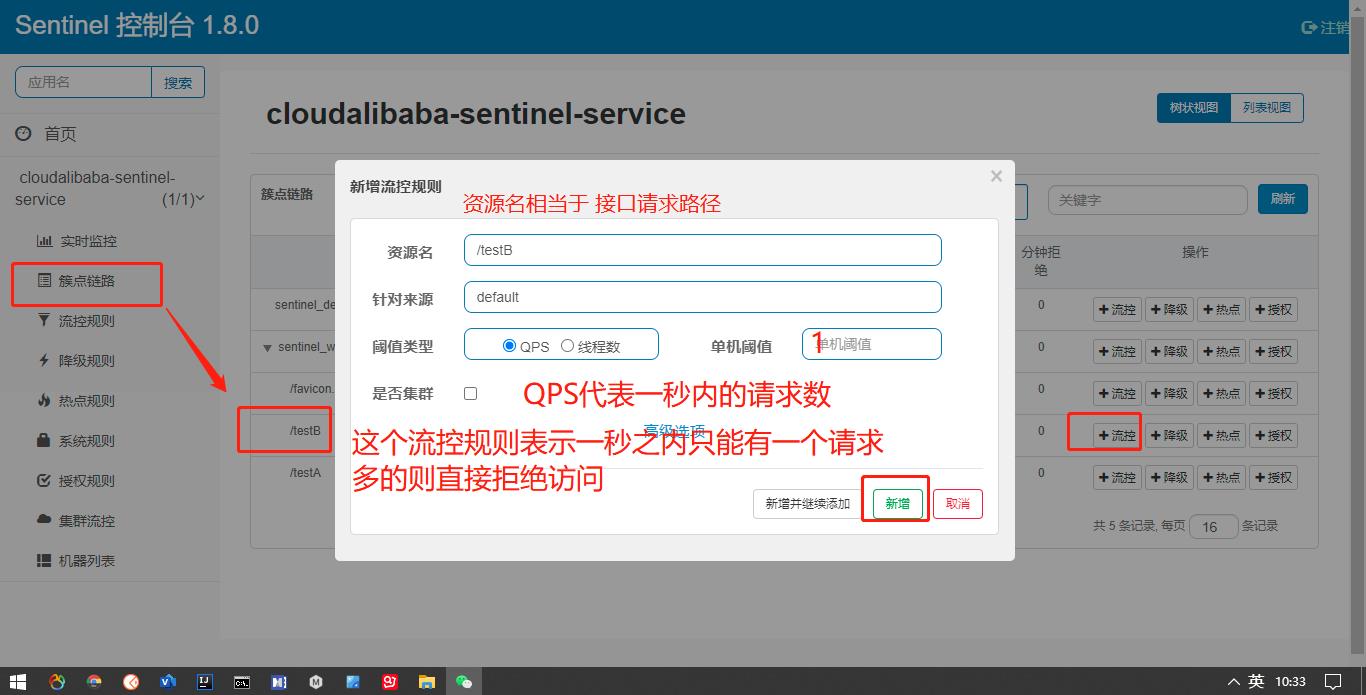
第一种直接在簇点链路下面点击流控按钮添加流控规则,第二种是在流控规则里面添加;
解释说明
资源名: 唯一名称,默认请求路径;
针对来源:Sentinel可以针对调用者进行限流,填写微服务名,默认default(不区分来源);
阈值类型/单机阈值:
- QPS(每秒请求数量):当调用api的QPS达到阈值的时候,进行限流;
- 线程数:当调用api的线程数达到阈值的时候,进行限流;
是否集群: 不需要集群;
流控模式- 直接:api达到限流条件,直接限流;
- 关联:当关联的资源达到阈值时,限流自己;
- 链路:只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流)[api级别的针对来源]
流控效果
- 快速失败:直接失败异常;
- Warm Up:根据codeFactor(冷加载因子,默认3)的值,从阈值/codeFactor,经过预热时长,才达到设置的QPS阈值;
- 排队等待:均速排队,让请求以均速的速度通过,阈值类型必须设置为QPS,否则无效;
Sentinel 1.8.0降级
因为我学的是Sentinel 1.7.0的,然后又在网上学的1.8.0版本,首先呢Sentinel在1.8.0对熔断降级做了很大的调整,现在已经支持自定义任意熔断时长了,引入了类似Hystirx的半开启恢复支持,如果想学习使用Hystrix请浏览: https://jiushiboy.github.io/posts/31969/;
RT是什么? 下列答案是默认的情况下;
答:RT(平均响应时间,秒级),平均响应时间超出阈值且在时间窗口内通过的请求>=5,同时满足这两个条件触发降级;
时间窗口也就是说在规定的时间内通过的请求大于等于5;
熔断状态
属性 说明 OPEN 表示熔断开启,拒绝所有请求 HALF_OPEN 探测恢复状态,如果接下来的一个请求顺利通过则结束熔断,否则继续熔断 CLOSED 表示熔断关闭,请求顺利通过;
三种熔断策略
熔断降级的三种策略分别为: 慢调用比例、异常比列、异常数三种熔断策略;
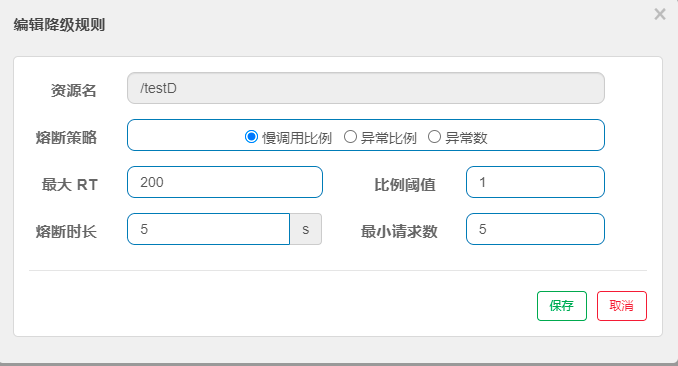
慢调用比列
慢调用: 指耗时大于阈值RT的请求被称为慢调用(阈值RT由用户行设置);
最小请求数: 允许通过通过的最小请求数,表示你只要不超出数量就不熔断,用户自定义;
属性 说明 最大RT(平均响应时间) 需要设置的阈值,超过该值则为慢调用 比列阈值 慢调用占所有调用的比率,范围:[0~1] 熔断时长 在这段时间内发生熔断、拒绝所有请求 最小请求数 即允许通过的最小请求数,在该数量内不发生熔断 执行逻辑
- 熔断(OPEN):请求数大于最小请求数且慢调用的比例大于比例阈值则发生熔断,熔断时间可以自定义设置;
- 探测(HALFOPEN):当熔断过了定义的时长,状态由熔断OPEN变成探测HALFOPEN;
如果接下来的一个请求小于最大RT,说明慢调用已经恢复,则结束熔断,状态由探测HALFOPEN变为关闭CLOSED;
如果接下来的一个请求大于最大RT,说明慢调用未恢复,继续熔断,熔断时长保持一致;- 注意Sentinel默认统计RT(平均响应时间)上限是
4900ms,超出阈值的都会算作4900ms,若需要变成此上限,可以通过启动配置项–Dcsp.sentinel.statistic.max.rt=xxx来配置
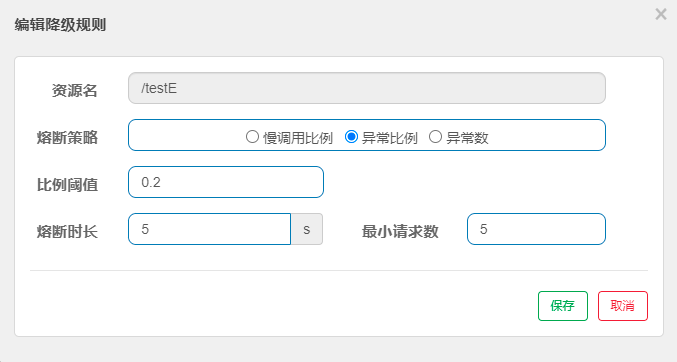
异常比例
当资源的每秒请求数大于等于最小请求数,并且异常总数占通过量的比例超过比例阈值时,资源进入降级状态;
属性 说明 异常比例阈值 异常比例=发生异常的请求数÷请求总数,取值范围:[0~1] 熔断时长 在这段时间内发生熔断、拒绝所有请求 最小请求数 即允许通过的最小请求数,在该数量内不发生熔断 执行逻辑
- 熔断OPEN:当请求数大于最小请求数并且异常比例大于设置阈值时触发熔断,熔断时长自定义设置;
- 探测HALFOPEN:当超过熔断时长时,由熔断OPEN状态变为HALFOPEN;
如果接下来的一个请求未发生错误,说明应用恢复,结束熔断,状态由探测HALFOPEN转为关闭CLOSED;
如果接下来的一个请求继续发生错误,说明应用未恢复,继续熔断,熔断时长保持一致;
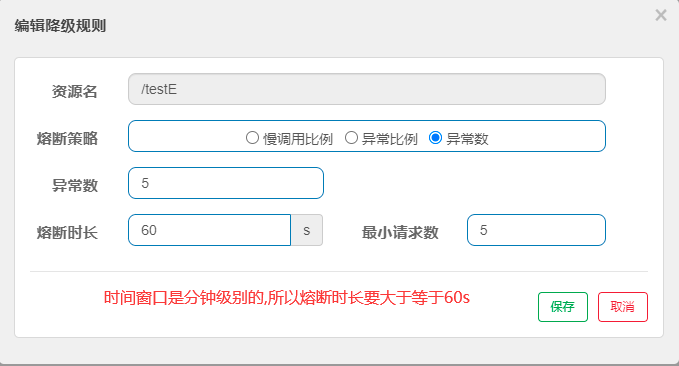
异常数
当资源近一分钟的异常数超过阈值(异常数)之后会进行服务降级,注意由于统计时间窗口是分钟级别的,若熔断时长小于60s,则熔断状态后仍可能再次进入熔断状态;
属性 说明 异常数 请求发生异常的数量 熔断时长 在这段时间内发生熔断、拒绝所有请求 最小请求数 即允许通过的最小请求数,在该数量内不发生熔断 执行逻辑
- 熔断OPEN:请求数大于最小请求数并且异常数量大于设置的阈值时触发熔断,熔断时长自定义;
- 探测HALFOPEN:当超过熔断时长,熔断状态转为探测状态;
如果接下来的一个请求未发生错误,说明应用恢复,结束熔断,状态由探测变为关闭;
如果接下来的一个请求继续发生错误,则继续熔断,熔断时间保持一致;
热点参数限流
客户端代码
代码传送门:https://github.com/jiushiboy/springcloud/tree/master/cloudalibaba-sentinel-service8401
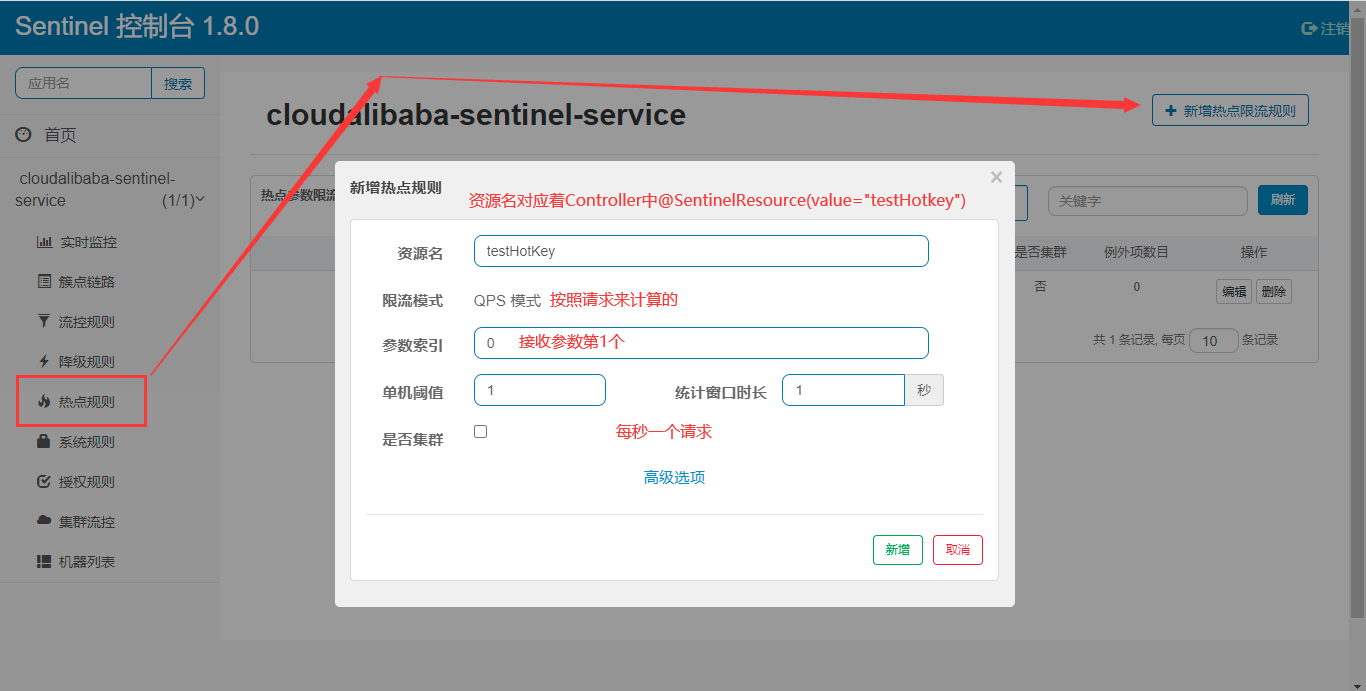
服务端配置热点key规则
执行效果为一秒钟之内请求超过一个并且带着第一个参数那么将执行blockHandler方法;Ps: @SentinelResource 注解其实就是模仿Hystrix中的@HystrixCommand
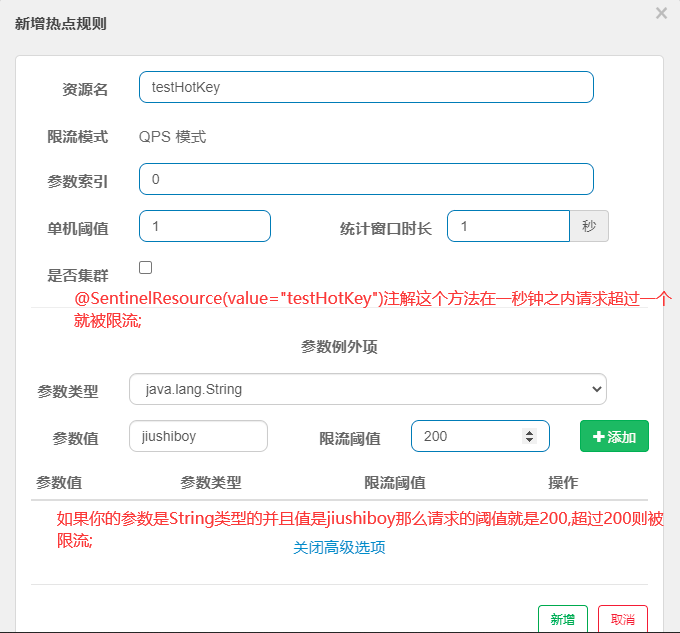
高级选项->参数例外项
配置完参数例外项别忘了点击绿色的添加键,解释都在图上了,如果不懂请留言在我邮箱;
系统限流
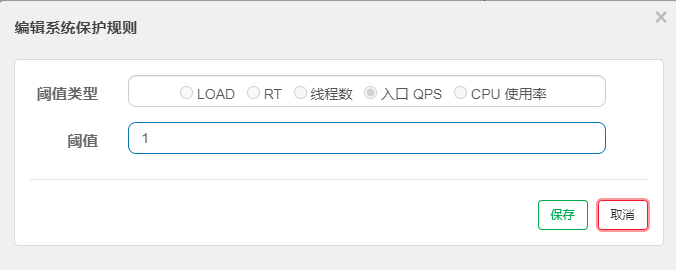
系统规则的五大模式
- Load 自适应(仅对Linux/Unix-like机器生效):系统的load1 作为启发指标,进行自适应系统保护,当系统load1超过设定启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR阶段);系统容量由系统的maxQps * minRt 估算得出;设置参考值一般是CPU cores * 2.5;
- CPU usage(1.5.0+版本):当系统CPU使用率超过阈值即触发系统保护(取值范围0.0~1.0);
- 平均RT:当单台机器上所有的入口流量的平均RT达到阈值即触发系统保护,单位是毫秒;
- 并发线程数:当单台机器上所有入口流量的并发线程达到阈值即触发系统保护;
- 入口QPS:当单台机器上所有入口流量的QPS达到阈值即触发系统保护;
需要解耦的问题
- 如果我们不自己定义blockHandler那么被限流以后展示的是Sentinel默认的提示,跟我们的业务内容毫无关系;
- 但是呢如果使用blockHandler去执行兜底方法的话又会和业务代码耦合,打个比方Service层只需要关注业务相关代码并不需要将访问数据库的代码放在Service层;
- 以上问题还不是最恐怖的,最可怕的是每个方法如果都需要一个blockHandler那么这种代码量会超级膨胀;
- 所以假想一下为什么不能出现一个全局的处理方式,例如Hystrix中的通过@FeignClient(value=”指定服务名称”,fallback=实现类.class),当使用这种方式则可以保证了不会造成代码的高耦合;相当于用实现类来充当兜底方法;
规则持久化
只要我们关闭了Sentinel,重启的时候一看,我配置的规则居然一个都无了,这个时候肯定需要持久化了;
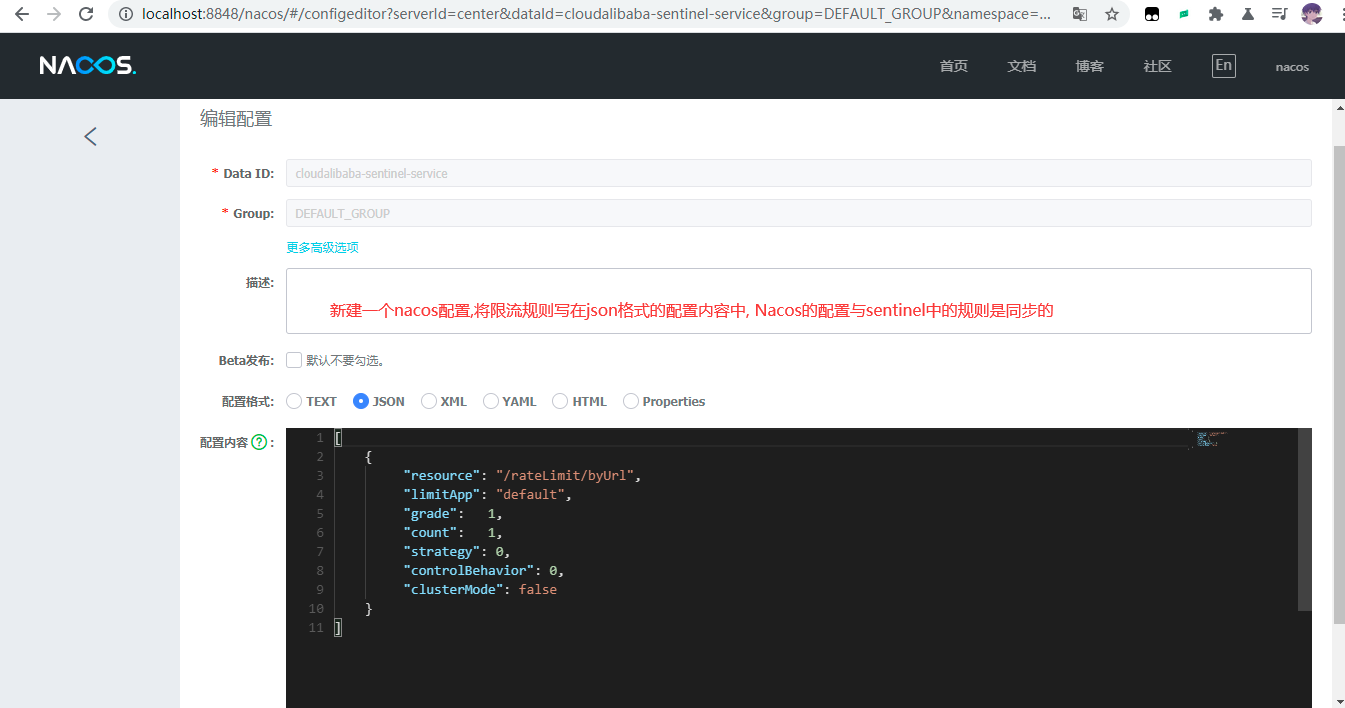
Ps:根据官方提供的方案,那就是保存到Nacos中;
- 首先在pom中导入Maven cloudalibaba-sentinel-service8401
1 | <dependency> |
- 配置yml文件 其实就是配置sentinel 的datasource
1 | server: |
- 然后编写Nacos
- 因为sentinel是懒加载所以先访问几次请求,随后就能在流控规则中直接看到你在nacos的配置内容中所配置的流控规则;
Seata
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
Seata术语
TC (Transaction Coordinator) - 事务协调者
- 维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
- 定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
- 管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
其余的先参考: https://blog.csdn.net/jixieguang/article/details/110621561
感觉现在的seata还是个半成品
 微信
微信 支付宝
支付宝

